 Krótkie bajty: Przeszukiwacz sieci WWW to program, który przegląda Internet (World Wide Web) w z góry określony, konfigurowalny i zautomatyzowany sposób oraz wykonuje określone działanie na przeszukanej treści. Wyszukiwarki takie jak Google i Yahoo wykorzystują spację jako sposób dostarczania aktualnych danych.
Krótkie bajty: Przeszukiwacz sieci WWW to program, który przegląda Internet (World Wide Web) w z góry określony, konfigurowalny i zautomatyzowany sposób oraz wykonuje określone działanie na przeszukanej treści. Wyszukiwarki takie jak Google i Yahoo wykorzystują spację jako sposób dostarczania aktualnych danych.
Firma Webhose.io, która zapewnia bezpośredni dostęp do danych na żywo z setek tysięcy forów, wiadomości i blogów, 12 sierpnia 2015 r. Opublikowała artykuły opisujące niewielki, wielowątkowy robot indeksujący, napisany w języku Python. Ten robot sieciowy Python jest w stanie przeszukać cały Internet. Ran Geva, autor tego małego robota indeksującego Python, mówi, że:
Napisałem jako „brudny”, „niepewny”, „zły”, „niezbyt dobry”. Mówię, że wykonuje swoją pracę i pobiera tysiące stron z wielu stron w ciągu kilku godzin. Żadna konfiguracja nie jest wymagana, żadne zewnętrzne importy, po prostu uruchom następujący kod Pythona z witryną źródłową i usiądź (lub zrób coś innego, ponieważ może to zająć kilka godzin lub dni w zależności od tego, ile danych potrzebujesz).Wielowątkowy przeszukiwacz oparty na Pythonie jest dość prosty i bardzo szybki. Jest w stanie wykryć i wyeliminować zduplikowane linki oraz zapisać zarówno źródło, jak i łącze, które można później wykorzystać do wyszukiwania linków przychodzących i wychodzących do obliczania pozycji strony. Jest całkowicie darmowy, a kod znajduje się poniżej:
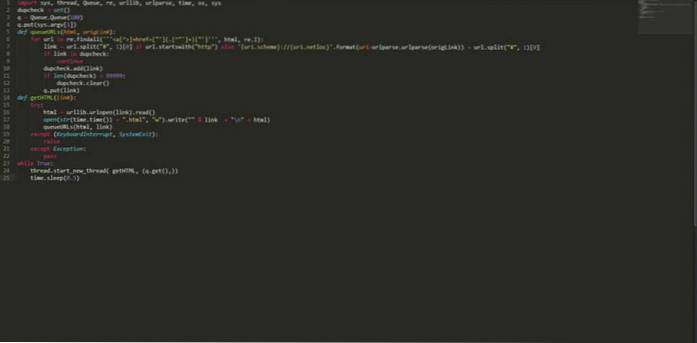
import sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): dla adresu URL w re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] if url.startswith ( "http") else 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] if link in dupcheck : kontynuuj dupcheck.add (link) if len (dupcheck)> 99999: dupcheck.clear () q.put (link) def getHTML (link): try: html = urllib.urlopen (link) .read () open (str (czas.czas ()) + ".html", "w"). write (""% link + "\ n" + html) queueURLs (html, link) z wyjątkiem (KeyboardInterrupt, SystemExit): raise z wyjątkiem Exception: pass while True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Zapisz powyższy kod pod jakąś nazwą, powiedzmy „myPythonCrawler.py”. Aby rozpocząć indeksowanie dowolnej witryny internetowej, wystarczy wpisać:
$ python myPythonCrawler.py https://fossbytes.com
Usiądź wygodnie i ciesz się tym robotem sieciowym w języku Python. Ściągnie dla Ciebie całą witrynę.
Zostań profesjonalistą w Pythonie dzięki tym kursom
Czy podoba Ci się ten martwy prosty, wielowątkowy robot indeksujący oparty na języku Python? Daj nam znać w komentarzach.
Przeczytaj także: Jak utworzyć rozruchowy dysk USB bez żadnego oprogramowania w systemie Windows 10